

title: java作业
author: charoneo
comments: true
typora-root-url: java作业
date: 2024-04-19 00:18:00
tags: java实验
description: 本文将从h08开始,介绍每一次作业的做法,其中h05是java程序设计lab1,h11是java程序设计lab2,这里就不做过多赘述了
h03
这里写一个也是唯一一个难度系数3星的任务
返回杨辉三角( Pascal triangle,请百度 杨辉三角 或者 Pascal triangle )第i行的系数,杨辉三角第一行定义为1 提示:从顶部的单个1开始,下面一行中的每个数字都是上面两个数字的和 例如getPascalTriangle(1)返回{1}, getPascalTriangle(2)返回{1,1} 测试的时候,系数肯定不会超过int的范围
public static int[] getPascalTriangle(int i) {
int[] row = new int[i];
Arrays.fill(row, 1); //全部填充为1
for(int r = 2;r <=i;r++) {
for(int j = r-2;j >=1;j--) {
row[j] = row[j] + row[j-1];
}
}
return row;
}每次都是先复制一下上一行的数据,然后从最后一行的倒数第二个数开始向前累加,从而实现当前值等于正上方值+左上方值
h08
注意本次实验部分任务相似,所以只给出一部分任务的做法
任务1:LoginUtil是一个登录的类,分别输入用户口令,当用户名为"a",口令为"a",不抛出异常,否则抛出InvalidUserExcetpion(InvalidUserExcetpion需要你自己定义)
做法:
设计LoginUtil类
public class LoginUtil{
public void login(String a, String b) throws InvalidUserException{
if(a.equals("a") && b.equals("a")) {
return;
}else {
throw new InvalidUserException();
}
}
}定义InvalidUserException
public class InvalidUserException extends RuntimeException{
public InvalidUserException() {
super();
}
public InvalidUserException(String message, Throwable cause) {
super(message,cause);
}
public InvalidUserException(String message) {
super(message);
}
public InvalidUserException(Throwable cause) {
super(cause);
}
}这里要注意一般自定义的异常都是集成RuntimeException,在构造的异常里面可以定义四个构造方法(模版),但不是必须
任务2:
构造一个 AgeCheck类,实现AgeCheckInterface接口, 当checkAge中的参数<0或者>200的时候抛出异常
public interface AgeCheckInterface {
public void checkAge(int age) ;
}做法:
public class AgeCheck implements AgeCheckInterface{
@Override
public void checkAge(int age){
if(age <0 || age >200) {
throw new IllegalArgumentException(); //注意这里不能抛出Exception
}
}
}h09
任务1:
计算出一段文字中不重复的字符的个数,例如“天津市天津大学 ”不重复字符为5
做法:
利用set的特性,里面的元素不能重复
public int getDistinctCharCount(String s) {
Set<String> set = new HashSet<>();
char[] charArray = s.toCharArray();
String[] stringArray = new String[charArray.length]; //构造一个字符串数组
for(int i = 0;i<charArray.length;i++) {
stringArray[i] = String.valueOf(charArray[i]);
}
for(int i=0;i<s.length();i++) {
set.add(stringArray[i]);
}
return set.size();
}注意本方法先把字符串转换为char类型的数组,构造了一个字符串数组,把char类型的数组每个部分的内容填到字符串数组的对应位置上,注意String.valueOf方法的使用
任务2:
返回一段文字中,出现频率最高的字符(不考虑并列第一的情况) 例如:getFrequentChar("好好学习") 返回'好'
例如:getFrequentChar("我是天津大学软件学院学生") 返回'学'
做法:
利用Map的特性,K-V键值对
public char getFrequentChar(String s) {
Map<Character, Integer> map = new HashMap<>();
for(int i=0;i<s.length();i++) {
if(map.containsKey(s.charAt(i))) {
map.put(s.charAt(i), map.get(s.charAt(i))+1);
}else {
map.put(s.charAt(i), 1);
}
}
char res = ' ';
int maxCount = 0;
for(Map.Entry<Character, Integer> entry: map.entrySet()) { //使用entrySet遍历
if(maxCount < entry.getValue()) {
res = entry.getKey();
maxCount = entry.getValue();
}
}
return res;
}注意其中的if...else部分还可以用以下代码来代替。
map.put(s.CharAt(i),map.getOrDefault(s.charAt(i),0)+1))注意charAt函数的使用:返回指定索引的字符
注意entrySet的遍历:Map.Entry<Character, Integer> entry: map.entrySet()
任务3:
返回一段文字中,出现频率最高的词(每个词由2个字符构成,任意两个相邻的字符称为一个词,例如“天津大学,你好”由“天津”“津大”“大学”“学,”“,你”“你好” 6个词构成),不会出现频率最高并列的情况
做法:
public String getFrequentWord(String content){
Map<String, Integer> map = new HashMap<>();
for(int i = 0;i<content.length()-1;i++) {
if(map.containsKey(content.substring(i, i+2))) { //注意substring的字符之间是索引
map.put(content.substring(i, i+2), map.get(content.substring(i, i+2))+1);
}else {
map.put(content.substring(i, i+2), 1);
}
}
String res = null;
int maxCount = 0;
for(Map.Entry<String, Integer> entry: map.entrySet()) {
if(maxCount < entry.getValue()) {
res = entry.getKey();
maxCount = entry.getValue();
}
}
return res;
}这个方法和任务2是比较类似的,区别是多了一个substring函数
任务4:
把一个StringBufer中所有的空格去掉,提示:不能新建StringBuffer对象,必须在原来的基础上删掉原来字符串
做法:
通过从头到尾循环,如果对应的字符为空格,就删除。
public void zipStringBufer(StringBuffer buf) {
for(int i = 0;i<buf.length();i++) {
if(buf.charAt(i) == ' ') {
buf.deleteCharAt(i--); //删了以后i也要减1
}
}
}注意deleteCharAt函数的使用,注意删除后索引i也要-1,否则遇到连续空格的情况下会有逻辑错误
h10
任务1:
将一个字符串中字符按出现频率的高到低排序返回,如果两个字符出现的频率一样,则将最先出现的字符排在前面,例如:
orderChar(“abcdefg”)返回 “abcdefg”
orderChar(“abcdefgg”)返回 “gabcdef”
orderChar(“abcdefgge”)返回 “egabcdf”
orderChar(“天津大学软件学院”)返回 “学天津大软件院”
做法:
注意这里要使用TreeMap,在Map内部对元素进行排序注意TreeMap的构造方法
注意indexOf函数的使用方法
Comparator在返回时,如果a<b,返回-1,把小的排在前面;如果a>b,返回-1,则把大的排在前面
最后则是先选出其中出现次数最多字符的次数,然后从这个次数开始,每次循环遍历Map,按照出现频率递减的方式来拼接字符串
public class Home10 {
public Home10() {
}
/**
* 将一个字符串中字符按出现频率的高到低排序返回,如果两个字符出现的频率一样,则将最先出现的字符排在前面
* 例如:orderChar(“abcdefg”)返回 “abcdefg”
* orderChar(“abcdefgg”)返回 “gabcdef”
* orderChar(“abcdefgge”)返回 “egabcdf”
* orderChar(“天津大学软件学院”)返回 “学天津大软件院”
* @param content
* @return
*/
public String orderChar(String content) {
Map<Character, Integer> map = new TreeMap<>(new Comparator<Character>() {
public int compare(Character c1, Character c2) {
if(c1.equals(c2)) { //不要忘记相等的情况,否则会出现g=1,g=1的情况;这里还必须用equals,否则用=会出现中文不支持
return 0;
}
return content.indexOf(c1) < content.indexOf(c2) ? -1 :1; //索引值小的放在前面
}
});
for(int i = 0; i<content.length();i++) {
if(map.containsKey(content.charAt(i))) {
map.put(content.charAt(i), map.get(content.charAt(i))+1);
}else {
map.put(content.charAt(i), 1);
}
}
String res = "";
int maxCount = 0;
for(Map.Entry<Character, Integer> entry: map.entrySet()) {
if(maxCount < entry.getValue()) { //先求出出现最多的次数
maxCount = entry.getValue();
}
}
for(int i = maxCount; i>0;i--) { //这层循环在外面qaq
for(Map.Entry<Character, Integer> entry: map.entrySet()) {
if(entry.getValue()==i) {
res += entry.getKey(); //拼接字符串直接用+即可
}
}
}
return res;
}
}h11
h12
任务1:
字符串content是一个超市的历次购物小票的合计,每次购物的明细之间用分号分割,每个商品之间用半角逗号分开
请找出 哪n(n>=1)个商品被同时购买的频率最高,将这n个商品名称的集合(set)返回。
历次购物的明细,例如:炸鸡,可乐,啤酒;薯片,啤酒,炸鸡;啤酒,雪碧,炸鸡。哪n个商品被同时购买的频率最高,将这n个商品名称的集合(set)返回
做法:
首先整体来讲是先将历次购物明细按照“;”分割成每次的明细,再将每次的明细按照“,”分解成不同的商品存到uniqueProducts中,利用一个generateCombinations函数来根据Set产生组合,把所有的组合都存到结果Map中。
看上去比较复杂的原因之一是Map的key值是Set<String>类型
public Set<String> getFrequentItem(String content,int n) {
String[] sessions = content.split(";");
Map<Set<String>, Integer> allPairMap = new HashMap<>();
for(String session : sessions) {
String[] products = session.split(",");
Set<String> uniqueProducts = new HashSet<>();
for(String product: products) {
uniqueProducts.add(product.trim());
}
if(uniqueProducts.size() >= n) {
Set<Set<String>> combinations = generateCombinations(uniqueProducts, n);
for(Set<String> combination : combinations) {
allPairMap.put(combination,allPairMap.getOrDefault(combination, 0)+1);
}
}
}
Set<String> maxFrequent = null;
int maxFrequentCount = 0;
for(Map.Entry<Set<String>, Integer> entry : allPairMap.entrySet()) {
if(maxFrequentCount < entry.getValue()) {
maxFrequentCount = entry.getValue();
maxFrequent = entry.getKey();
}
}
return maxFrequent;
}接下类是generateCombinations函数的实现,将products集合转换为ArrayList(这里注意转换的方法),传入n个商品的n值,开始索引start,当前Set集合(回溯法用到),和结果集合。
generateCombinationsHelper函数主要用到了回溯法,如果当前集合的大小为n,则把当前集合加入到结果集中,否则从第start项开始,分别把不用的product加进去,add完后还要remove,这样就可以添加别的元素,这也是回溯法的本质。
可以类比理解为dfs
private Set<Set<String>> generateCombinations(Set<String> products, int n){
Set<Set<String>> result = new HashSet<>();
generateCombinationsHelper(new ArrayList<>(products), n , 0, new LinkedHashSet<>(), result);
return result;
}
private void generateCombinationsHelper(List<String> products, int n, int start, Set<String> current, Set<Set<String>> result) {
if(current.size() == n) {
result.add(new HashSet<>(current));
return;
}
for(int i = start; i< products.size();i++) {
current.add(products.get(i));
generateCombinationsHelper(products, n,i+1,current,result);
current.remove(products.get(i));
}
}h13
任务1:
返回红楼梦中出现频率最高的N个词,频率从高到低排列(所谓词就是两个相邻的汉字)
做法:
首先还是通过Map进行每个词语出现次数的统计,注意这里使用了matches函数,汉字的编码范围是[\\u4e00-\\u9fa5]
接下来构造一个List,其中的元素是Map.Entry这个对象,构造函数的参数为entrySet。
下面利用List中的sort方法,里面的参数是lamda函数,a和b分别代表List中的两个元素,把这两个元素的频率取出来做比较,把大的放在前面,最后我们就得到了频率从高到低的排序。
根据这个排序结果,从FrequentList取出前n个元素(Map.Entry对象),然后通过getKey()来得到相应的字符串,放到result中
public List<String> getTopNWords( int n) throws Exception{
String text = readFromTxt(this.filename);
Map<String, Integer> FrequencyWord = new HashMap<>();
for(int i = 0;i<text.length()-1;i++) {
String word = text.substring(i,i+2);
if(word.matches("[\\u4e00-\\u9fa5]{2}")) { //确保是两个汉字
FrequencyWord.put(word, FrequencyWord.getOrDefault(word, 0)+1);
}
}
List<Map.Entry<String, Integer>> FrequentList = new ArrayList<>(FrequencyWord.entrySet());
FrequentList.sort((a,b)->b.getValue().compareTo(a.getValue()));
List<String> result = new ArrayList<>();
for(int i=0;i<n && i <FrequentList.size();i++) {
result.add(FrequentList.get(i).getKey());
}
return result;
}任务2:
将红楼梦文本文件拆分为120个章节,返回120个元素的字符串数组
做法:
注意这里要修改已经给出的代码,因为是用split根据特定的正则表达式分割的,第一回前面还有部分与内容无关的部分,因此要通过Arrays.copyOfRange函数返回原来字符串数组除去第一部分的内容。
private String[] splitContentToChapter(String content) {
// 提示 使用 content.split(" 第[一,二,三,四,五,六,七,八,九,十,零]{1,5}回 ");正则表达拆分
// 百度一下正则表达式
String contents[] = content.split(" 第[一,二,三,四,五,六,七,八,九,十,零]{1,5}回 ");
return Arrays.copyOfRange(contents, 1, contents.length); //去除第一章节之前的非正式内容
}任务3:
统计红楼梦章节字符串str出现的频率,把每一章出现的频率存到result[章节数]并返回这个数组
做法:
首先调用readFromTxt和splitContentToChapter这两个上面已经定义好的方法,得到的结果存到chapters数组中,然后遍历数组。
多说一嘴readFromTxt函数,
private String readFromTxt(String filename) throws Exception {
Reader reader = null;
try {
StringBuffer buf = new StringBuffer();
char[] chars = new char[1024];
// InputStream in=new FileInputStream(filename);
reader = new InputStreamReader(new FileInputStream(filename), "UTF-8");
int readed = reader.read(chars);
while (readed != -1) {
buf.append(chars, 0, readed);
readed = reader.read(chars);
}
return buf.toString();
} finally {
close(reader);
}
}这里的FileInputStream是字节流,是超类InputStream的具体实现。InputStreamReader是把字节流转换为字符流,然后用Reader来接收。这里也可以用BufferedReader,BufferedReader的好处是可以通过readLine来逐行读取
这里要注意indexOf(String, int)的使用,返回str从index位置开始出现的位置,如果未找到则返回-1.
注意每次找到str后要把当前的str跳过去,也就是把index加上str的长度
public int[] getStringFrequent(String str) throws Exception {
int[] result = new int[120];
String text = readFromTxt(this.filename);
this.chapters = splitContentToChapter(text);
int i = 0;
for(String chapter : chapters) {
int count = 0;
int index = 0;
while(index != -1) {
index = chapter.indexOf(str, index); //从index开始查找str,返回查找到的索引
if(index != -1) {
count++;
index += str.length();
}
}
result[i++] = count;
}
return result;
}h14
任务1:
现在所有学生的名单students.txt(为了避免乱码问题,文件中不包含汉字),其中每行为一个学生信息,包括学号、姓名、班级,以tab符号分割(\t),
学院要求所有同学把自己一寸照片发给辅导员,图片命名规则为 “学号.jpg”
现在存在下列问题。请用编程的方式帮助辅导员解决如下问题:
找出哪些同学的照片没有交照片;
在目标目录下每个班级建立一个子目录,把上交的同学的照片,统一按 学号_姓名.jpg 方式拷贝到各自班级目录下,原来的文件不要删除.
已知的测试信息:
// 实际测试中,文件存放位置可能改变,学生数量也可能改变
// 其中每行为一个学生信息,包括学号、姓名、班级,以tab符号分割(\t),
String studentListFileName="E:/EclipseWorkspace/hw1/src/com/huawei/classroom/student/h14/students.txt";
// 学生照片存放的目录,不会包含子目录,本目录的pic给出了存放图片的目录示例,实际测试中,pic 位置可能改变,其下面文件数量也会改变
String picDir="E:/EclipseWorkspace/hw1/src/com/huawei/classroom/student/h14/pic/";
String targetDir="E:/EclipseWorkspace/hw1/src/com/huawei/classroom/student/h14/target/";做法:
首先要注意的就是返回值的类型是Set<String>,所以要首先构造一个noPicIds的集合用来存储没有提交照片的学生的学号。
然后用BufferedReader来读取studentListFile(这是一个String类型的路径)中的内容,利用readLine()函数来读取每一行的内容,然后通过split方法分别取出studentId, studentName, studentClass.
然后根据studentId来打开jpg文件
如果存在,则说明提交了文件,然后创建相应的班级文件夹,把图片拷贝到班级文件夹下
注意File.copy函数的使用方法:这里的原型是File.copy(Paths, Paths, Options),表示把第一个Paths对象拷贝到第二个Paths对象。具体来讲,就是getPath()函数得到文件的字符串路径,利用Paths.get函数得到一个静态的Paths对象,其中StandardCopyOption.REPLACE_EXISTING代表拷贝时如果名字相同,则替换已有的文件。
如果不存在,则说明没有提交文件。那么就把这个学生的学号放到noPidIds集合中。
同时还要注意,在使用BufferdReader时要考虑异常
public Set<String> copyToTargetDirAndReturnNoExist(String studentListFile,String srcDir,String target) throws Exception {
Set<String> noPicIds = new HashSet<>();
File dir = new File(target);
if(!dir.exists()) {
dir.mkdirs();
}
try(BufferedReader reader = new BufferedReader(new FileReader(studentListFile))){
String line;
while((line = reader.readLine()) != null) {
String[] details = line.split("\t");
String studentId = details[0];
String StuName = details[1];
String StuClass = details[2];
File picFile = new File(srcDir + studentId + ".jpg");
if(picFile.exists()) {
File targetFile = new File(target + StuClass);
if(!targetFile.exists()) {
targetFile.mkdirs();
}
Files.copy(Paths.get(picFile.getPath()), Paths.get(targetFile.getPath(),studentId +"_" + StuName + ".jpg"),StandardCopyOption.REPLACE_EXISTING);
}else {
noPicIds.add(studentId);
}
}
}catch(IOException e) {
throw new IOException("Error Handling File Operations",e);
}
return noPicIds;
}h15
任务1:
测试程序输入一个StringBuffer,刚输入的时候StringBuffer值为空,等待1000ms后,这个StringBuffer的值变为"ok"
做法:
考点主要是重写run方法和Thread.sleep的使用
public class ThreadUtil extends Thread{
private StringBuffer buf;
public ThreadUtil(StringBuffer buf) {
this.buf = buf;
}
@Override
public void run() {
try {
Thread.sleep(1000);
buf.append("ok");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
System.out.println("Thread was Interrupted!");
}
}
}任务2:
多线程方式,统计[start,end)区间所有的质数,并且小到大排序返回
做法:
首先利用ExecutorService创建一个指定大小的线程池,大小具体为传进来的参数threadCount。
然后设置一个List里面专门用来存放future对象
接下来计算每个线程处理的区间大小,让每个线程处理的数字数量几乎相等,注意如果是最后一个线程,必须处理到末尾(end)
executor在submit时,应该用实现Callable接口而不是Runnable接口,因为Callable接口可以有返回值,在重写的call()方法中完成对素数的挑选。
注意submit返回的对象是Future,所以我们把每一个Future对象都存到一个List中,最后把List中所有的Future对象中的对象(类型是List<long>)合并(用addAll函数)为一个大的List。
最后调用Collections.sort()方法对这个List进行排序,返回结果
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import java.util.concurrent.Callable;
public class PrimeUtil {
public List<Long> getPrimeList(long start, long end, int threadCount) throws Exception {
ExecutorService executor = Executors.newFixedThreadPool(threadCount);
List<Future<List<Long>>> futures = new ArrayList<>();
long blockSize = (end - start) / threadCount;
for (int i = 0; i < threadCount; i++) {
long localStart = start + i * blockSize;
long localEnd = (i == threadCount - 1) ? end : localStart + blockSize;
futures.add(executor.submit(new PrimeTask(localStart, localEnd)));
}
List<Long> primes = new ArrayList<>();
for (Future<List<Long>> future : futures) {
primes.addAll(future.get()); // Retrieve and combine results
}
executor.shutdown();
Collections.sort(primes); // Ensure the primes are sorted
return primes;
}
private static class PrimeTask implements Callable<List<Long>> {
private long start, end;
public PrimeTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
public List<Long> call() throws Exception {
List<Long> localPrimes = new ArrayList<>();
for (long number = start; number < end; number++) {
if (isPrime(number)) {
localPrimes.add(number);
}
}
return localPrimes;
}
private boolean isPrime(long number) {
if (number <= 1) return false;
if (number <= 3) return true;
if (number % 2 == 0 || number % 3 == 0) return false;
for (long i = 5; i * i <= number; i += 6) {
if (number % i == 0 || number % (i + 2) == 0) return false;
}
return true;
}
}
}h16
任务:
首先看一下Test.java中的main方法
public static void main(String[] args) {
// TODO Auto-generated method stub
// 端口号测试的时候随机给
int port = 8088;
// 要求完成MyServer类
new MyServer().startListen(port);
Socket socket = null;
PrintWriter out = null;
BufferedReader in = null;
try {
socket = new Socket("127.0.0.1", port);
out = new java.io.PrintWriter(socket.getOutputStream());
// 获得输入流
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
// 随机测试向服务器端输入几句话,要求服务器端原封不动返回
if (testEcho(in, out, "hellow")) {
System.out.println("ok 1");
}
if (testEcho(in, out, "haha")) {
System.out.println("ok 2");
}
// 向服务器端输入bye,断开表示断开连接
out.write("bye" + "\r\n");
out.close();
in.close();
socket.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
close(in);
close(out);
close(socket);
}
}做法:
MyServer类实现监听方法,主要是创建一个新线程,不断的启动线程,采用多线程的方式来实现服务器和客户端的交互
public class MyServer {
public MyServer() {
}
public void startListen(int port) {
Thread serverThread = new ServerThread(port);
serverThread.start();
}
}下面是ServerThread的实现
package com.huawei.classroom.student.h16;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class ServerThread extends Thread{
private int port;
private ServerSocket server;
private Socket socket;
private InputStream in;
private OutputStream out;
public ServerThread(int port) {
server = null;
socket = null;
in = null;
out = null;
this.port = port;
}
@Override
public void run() {
try {
server = new ServerSocket(port);
socket = server.accept();
in = socket.getInputStream();
out = socket.getOutputStream();
byte[] data = new byte[100];
int readed = in.read(data);
String line = new String(data, 0, readed);
while(!("bye" + "\r\n").equals(line)) {
out.write(line.getBytes());
readed = in.read(data);
line = new String(data, 0, readed);
}
}catch(IOException e) {
e.printStackTrace();
}finally {
close(server);
close(socket);
close(in);
close(out);
}
}
public static void close(AutoCloseable closeable) {
if (closeable != null) {
try {
closeable.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}核心部分如下:
server = new ServerSocket(port);
socket = server.accept();
in = socket.getInputStream();
out = socket.getOutputStream();
byte[] data = new byte[100];
int readed = in.read(data);
String line = new String(data, 0, readed);
while(!("bye" + "\r\n").equals(line)) {
out.write(line.getBytes());
readed = in.read(data);
line = new String(data, 0, readed);
}服务器用accept一直等待客户端,每次都通过read函数读取100字节大小的内容,readed来记录读取具体的字节数,然后构造一个字符串,比较这个字符串是否是bye,如果不是则重复进行上述操作
h17
任务:
这次作业是实现小游戏的Pro版,比之前的游戏(h05~h07)增加了通过BattleField.init(String fileName)从从配置文件中初始化
在Test里面,还有Player这个对象,可以知道,新增了多个玩家同时玩这个游戏的功能
在方法实现层面,多了一个无参数的attack的构造方法,即寻找距离他最近、非己方、且活着的对象B进行攻击,如果攻击范围内没有符合要求对象则什么也不做。
做法:
1.枚举类
首先把所有用到的“名词”都列到枚举类中
package com.huawei.classroom.student.h17;
public enum EnumObjectType {
base,
health,
strength,
range,
heavyTank,
mediumTank,
rifleSoldier,
RPGSoldier,
dog,
barrack,
warFactory
}然后我们实现读配置文件,这里的做法是把配置文件的所有信息读到一个参数类中,然后用到该信息的时候(如创建对象时)直接从这个参数类中读取信息
配置文件部分如下:
#测试的时候,属性的整数值可能会改变
base.health=1000
base.range=0
base.strength=0
#重型坦克的属性
heavyTank.health=500
heavyTank.range=100
heavyTank.strength=100在BattleField.java中,我定义了两个方法,一个是readLine用来读文件,一个是setValue用来把读到的具体数值写到参数类中。
2.参数类(简略版)
package com.huawei.classroom.student.h17;
public class Param {
public static int baseHealth =0;
public static int baseRange = 0;
public static int baseStrength = 0;
public static int heavyTankHealth = 0;
public static int heavyTankRange = 0;
public static int heavyTankStrength = 0;
public static int mediumTankHealth = 0;
public static int mediumTankRange = 0;
public static int mediumTankStrength = 0;
...3.Battlefield类
readLine方法的实现
private static List<String[]> readLines(String filename){
String line = "";
Reader reader = null;
List<String[]> results = new ArrayList<>();
try {
reader = new FileReader(filename);
}catch(FileNotFoundException e) {
e.printStackTrace();
}
if(reader == null) {
return null;
}
LineNumberReader lineReader = new LineNumberReader(reader);
try {
while(true) {
line = lineReader.readLine();
if(line == null) {
break;
}
if(line.trim().length()==0 || line.trim().startsWith("#")) {
continue;
}
results.add(line.trim().split("\\.|=")); //注意反斜杠本身也要转义
}
}catch(IOException e) {
e.printStackTrace();
}
return results;
}注意,这里也可用用BufferedReader来代替,即
try(BufferedReader reader = new BufferedReader(new FileReader(filename))){
...
}catch(IOException e){
e.printStackTrace();
}setValue实现如下(简略版):
public static void setValue(String[] rules) {
if(EnumObjectType.base.toString().equals(rules[0])) {
if(EnumObjectType.health.toString().equals(rules[1])) {
Param.baseHealth = Integer.parseInt(rules[2]);
}else if(EnumObjectType.strength.toString().equals(rules[1])) {
Param.baseStrength = Integer.parseInt(rules[2]);
}else if(EnumObjectType.range.toString().equals(rules[1])) {
Param.baseRange = Integer.parseInt(rules[2]);
}
}else if(EnumObjectType.heavyTank.toString().equals(rules[0])) {
if(EnumObjectType.health.toString().equals(rules[1])) {
Param.heavyTankHealth = Integer.parseInt(rules[2]);
}else if(EnumObjectType.strength.toString().equals(rules[1])) {
Param.heavyTankStrength = Integer.parseInt(rules[2]);
}else if(EnumObjectType.range.toString().equals(rules[1])) {
Param.heavyTankRange = Integer.parseInt(rules[2]);
}
...然后,便可以写出init方法
public static void init(String filename) {
List<String[]> rules = readLines(filename);
if(rules == null) {
return;
}
for(String[] rule : rules) {
setValue(rule);
}
}BattleField.java实际上是维护了一个类型为Player的List列表,因此Battlefield.java中剩下的代码如下:
package com.huawei.classroom.student.h17;
import java.util.*;
import java.io.*;
public class BattleField {
private static List<Player> players = new ArrayList<>();
public BattleField() {
players = null;
}
...
public static void createPlayer(String playerName) {
if(playerName == null) {
return;
}
Player newPlayer = new Player(playerName);
players.add(newPlayer);
}
public static GameBase createGameBase(Player p, int x, int y) {
return new GameBase(p,x,y);
}
public static List<Player> getAllPlayer(){
return players;
}
}4.Player类的实现
Player的实现较为简单,只有一个name属性,还有对应的getter和setter
package com.huawei.classroom.student.h17;
public class Player {
private String name;
public Player(String name) {
this.name = name;
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return this.name;
}
}5.GameObject的实现
这个类里面完成了主要的游戏功能和逻辑,所以包含所有对象的属性,如果有具体对象属性不匹配(比如建筑物的攻击力等等),把对应的属性值设置为0即可。如果有具体对象的方法不匹配或者功能不全面,在对应的子类中重写该方法即可。
除了之前简单版本游戏中定义的五个属性(x,y,PH,attackValue,attackRange)之外,还有玩家信息(Player p)、List<GameObject> gameObjects存储所有对象(无参攻击时会检索周围所有的对象)、EnumObjectType objectType存储当前对象的类别,在打印result.txt会用到
此外,每次攻击后还需要打印(到控制台)相关的攻击信息(具体见result.txt)
package com.huawei.classroom.student.h17;
import java.util.*;
public class GameObject {
protected int x,y;
protected int health;
protected int strength;
protected int range;
protected Player player;
protected static List<GameObject> gameObjects = new ArrayList<>();
protected EnumObjectType objectType; //定义这个属性是为了在打印时打印出类别
public GameObject(Player p, int x, int y, int PH, int attackValue, int attackRange) {
this.player = p;
this.x = x;
this.y = y;
this.health = PH;
this.strength = attackValue;
this.range = attackRange;
GameObject.gameObjects.add(this);
}
@Override
public String toString() { //在result.txt中打印
return "["+player.getName()+"."+objectType+" live="+(!isDestroyed())+" x="+x+" y="+y+" health="+getHealth()+"]";
}
public void move(int dx, int dy) { //building不能移动,所以在building中重写
this.x += dx;
this.y += dy;
}
public double getDistance(GameObject obj1, GameObject obj2) {
return Math.sqrt(Math.pow(obj1.x-obj2.x, 2)+Math.pow(obj1.y-obj2.y, 2));
}
public void attack(GameObject B) {
if(this.isDestroyed() || B.isDestroyed() || getDistance(this,B)>this.range) {
return;
}
String debug = this + "攻击"+B;
B.health -= this.strength;
debug += "攻击后 health="+B.getHealth();
System.out.println(debug); //在result.txt中打印
}
public void attack() {
double min = this.range;
for(GameObject g: gameObjects) {
if(g.isDestroyed() || this.isDestroyed()) {
continue;
}
if(getDistance(this,g) < min) {
min = getDistance(this,g);
}
}
for(GameObject g: gameObjects) {
if(g.isDestroyed() || this.isDestroyed()) {
continue;
}
if(getDistance(this,g) - min < 0.000001) {
attack(g);
}
}
}
public int getHealth() {
return this.health;
}
public boolean isDestroyed() {
return this.health<=0;
}
public void setObjectType(EnumObjectType type) {
this.objectType = type;
}
public void dead() {
//在Soldier类中重写
}
}6.其他各类
其他各种类和之前的类似,唯一需要增加的就是每次构造完对象后都需要设置类型,树形图表示如下:
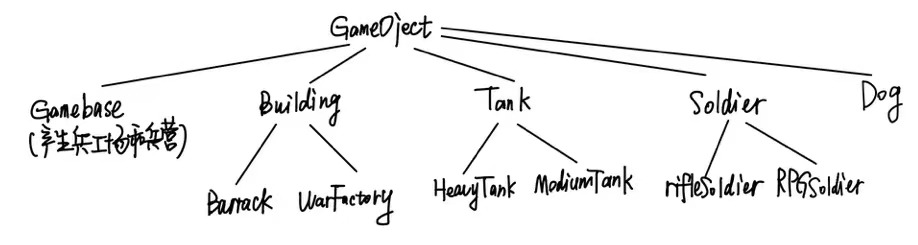
package com.huawei.classroom.student.h17;
public class GameBase extends GameObject{
public GameBase(Player p, int x, int y) {
super(p,x,y,Param.baseHealth,Param.baseStrength,Param.baseRange);
setObjectType(EnumObjectType.base);
}
public Building building(EnumObjectType type, int x, int y) { //基地创建建筑物时可以指定x和y
if(type == EnumObjectType.barrack) {
return new Barrack(this.player, x, y);
}else if(type == EnumObjectType.warFactory) {
return new WarFactory(this.player, x, y);
}else {
return null;
}
}
}在写Building类时,要重写move方法,因为建筑物不能移动
public class Building extends GameObject{
public Building(Player p, int x, int y, int PH, int attackValue, int attackRange) {
super(p,x,y,PH,attackValue,attackRange);
}
@Override
public void move(int dx, int dy) {
}
}兵营Barrack产生各种士兵和狗
public class Barrack extends Building{
public Barrack(Player p, int x, int y) {
super(p,x,y,Param.barrackHealth,Param.barrackStrengh,Param.barrackRange);
setObjectType(EnumObjectType.barrack);
}
public GameObject traing(EnumObjectType type) {
if(type == EnumObjectType.rifleSoldier) {
return new RifleSoldier(this.player, this.x, this.y);
}else if(type == EnumObjectType.RPGSoldier) {
return new RPGSoldier(this.player, this.x, this.y);
}else if(type == EnumObjectType.dog) {
return new Dog(this.player, this.x, this.y);
}else {
return null;
}
}
}两个士兵都继承自父类Soldier
public class Soldier extends GameObject{
private static int livingSoldierCount = 0;
private static int deadedSoldierCount = 0;
public Soldier(Player p, int x, int y, int PH , int attackValue, int attackRange) {
super(p,x,y,PH,attackValue,attackRange);
livingSoldierCount++;
}
public int getLivingSoldierCount() {
return livingSoldierCount;
}
public int getDeadedSoldierCount() {
return deadedSoldierCount;
}
@Override
public void dead() {
livingSoldierCount--;
deadedSoldierCount++;
}
}public class RifleSoldier extends Soldier{
public RifleSoldier(Player p, int x, int y) {
super(p,x,y,Param.rifleSoldierHealth,Param.rifleSoldierStrength,Param.rifleSoldierRange);
setObjectType(EnumObjectType.rifleSoldier);
}
}
public class RPGSoldier extends Soldier{
public RPGSoldier(Player p, int x, int y) {
super(p,x,y,Param.RPGSoldierHealth,Param.RPGSoldierStrength,Param.RPGSoldierRange);
setObjectType(EnumObjectType.RPGSoldier);
}
}狗直接继承GameObject类
public class Dog extends GameObject{
public Dog(Player p, int x, int y) {
super(p,x,y,Param.dogHealth,Param.dogStrength,Param.dogRange);
setObjectType(EnumObjectType.dog);
}
}兵工厂产生两种类型的Tank
public class WarFactory extends Building{
public WarFactory(Player p, int x, int y) {
super(p,x,y,Param.warFactoryHealth,Param.warFactoryStrengh,Param.warFactoryRange);
setObjectType(EnumObjectType.warFactory);
}
public Tank building(EnumObjectType type) {
if(type == EnumObjectType.heavyTank) {
return new HeavyTank(this.player,this.x, this.y);
}else if(type == EnumObjectType.mediumTank) {
return new MediumTank(this.player, this.x, this.y);
}else {
return null;
}
}
}public class HeavyTank extends Tank{
public HeavyTank(Player p, int x, int y) {
super(p,x,y,Param.heavyTankHealth,Param.heavyTankStrength,Param.heavyTankRange);
setObjectType(EnumObjectType.heavyTank);
}
}
public class MediumTank extends Tank{
public MediumTank(Player p, int x, int y) {
super(p,x,y,Param.mediumTankHealth,Param.mediumTankStrength,Param.mediumTankRange);
setObjectType(EnumObjectType.mediumTank);
}
}h18
首先补充一下正则表达式的知识
基本匹配:
正则表达式a.c中间的.可以且仅限匹配一个字符
\d仅限单个数字字符,而\D则匹配一个非数字。
用\w可以匹配一个字母、数字或下划线,w的意思是word。
用\s可以匹配一个空格字符,注意空格字符不但包括空格,还包括tab字符(在Java中用\t表示)。
修饰符*可以匹配任意个字符(包括0个)如A\d*,修饰符+可以匹配至少一个字符,如A\d+。
如果我们想精确指定n个字符怎么办?用修饰符{n}就可以。如A\d{3}
如果我们想指定匹配n~m个字符怎么办?用修饰符{n,m}就可以。如A\d{3,5}
如果没有上限,那么修饰符{n,}就可以匹配至少n个字符。
匹配开头和结尾
用正则表达式进行多行匹配时,我们用^表示开头,$表示结尾。例如,^A\d{3}$,可以匹配"A001"、"A380"。
匹配指定范围
要匹配大小写不限的6位十六进制数,比如1A2b3c,我们可以这样写:[0-9a-fA-F]{6}
或规则
用|连接的两个正则规则是或规则,例如,AB|CD表示可以匹配AB或CD。
使用括号
现在我们想要匹配字符串learn java、learn php和learn go怎么办?可表示成learn\\s(java|php|go)。
任务:
h18主要是考察反射
???
做法:
package com.huawei.classroom.student.h18;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
public class MyClassFactory {
private Map<String, Map<String, Object>> classConfigs = new HashMap<>();
public MyClassFactory(String configFilePath) throws Exception {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(configFilePath), "UTF-8"))) {
String line;
while ((line = reader.readLine()) != null) {
line = line.trim();
if (line.isEmpty() || line.startsWith("#")) {
continue; // 跳过空行和注释行
}
String[] parts = line.split("=");
String key = parts[0].trim();
String value = parts[1].trim().replaceAll("^\"|\"$", ""); // 去除开头和结尾的双引号
String[] classAndProperty = key.split("\\.(?=[^\\.]+$)");
String className = classAndProperty[0]; //类名
String propertyName = classAndProperty[1]; //属性名
// 根据值是否以引号包围来判断是否为字符串
Object typedValue = parts[1].startsWith("\"") && parts[1].endsWith("\"") ? value : Integer.parseInt(value);
classConfigs.computeIfAbsent(className, k -> new HashMap<>()).put(propertyName, typedValue);
}
}
}
public <T> T createInstance(Class<T> clazz) throws Exception {
T instance = clazz.getDeclaredConstructor().newInstance();
Map<String, Object> properties = classConfigs.get(clazz.getName());
if (properties != null) {
for (Map.Entry<String, Object> entry : properties.entrySet()) {
String propName = entry.getKey();
Object propValue = entry.getValue();
String methodName = "set" + propName.substring(0, 1).toUpperCase() + propName.substring(1); //例如setColor
Method method = clazz.getMethod(methodName, propValue.getClass());
method.invoke(instance, propValue);
}
}
return instance;
}
}上述代码有几点注意事项,
String[] classAndProperty = key.split("\\.(?=[^\\.]+$)");首先这句话是正则表达式+正向先行断言
代表匹配从开头到结尾出现的.中的最后一个.
classConfigs.computeIfAbsent(className, k -> new HashMap<>()).put(propertyName, typedValue);这里是调用了一个Map中的computeIfAbsent方法,检查是否有className,如果有,则返回对应的value值(还是一个Map);如果没有,则构造一个新的className到value的映射关系(这里用到了lambda表达式),然后把对应的属性名和属性值放进去
接下来就是创建一个实例
实现通过
T instance = clazz.getDeclaredConstructor().newInstance();创建一个无参构造实例
接下来读取上面的配置信息
Map<String, Object> properties = classConfigs.get(clazz.getName());将该类下的所有属性以及对应的值存放到Map中
然后就是遍历Map,获得属性名和属性值,通过属性名构造方法的名字,然后
Method method = clazz.getMethod(methodName, propValue.getClass());通过getMethod获得该方法名和指定参数类型对应的方法,最后通过
method.invoke(instance, propValue);invoke函数传入实例和方法参数,来设置实例的相关属性
h19
h19又返璞归真了,回到了之前简单的问题,总共有五个小任务,这里只介绍后两个
任务1:
完成StrUtil类,其中的removeDulpicatedChar()方法可以去掉一个字符串中的重复字符,重复出现的字符只保留一个,并仍然按原来的顺序输出
做法:
利用集合去重的方法,但是一般的集合是无序的,所以采用LinkedHashSet。
遍历集合时,采用Iterator来进行遍历,每次用next()函数取出每个元素
public String removeDulpicatedChar(String string) {
// TODO Auto-generated method stub
Set<Character> UniqueEle = new LinkedHashSet<>(); //使用Linked保留原来的顺序
for(int i=0;i<string.length();i++) {
UniqueEle.add(string.charAt(i));
}
Iterator<Character> it = UniqueEle.iterator();
String result = "";
while(it.hasNext()) {
result += it.next();
}
return result;
}注意这里的result还可以用StringBuild,每次append(),返回result.toString().
任务2:
将所有学生姓名按总成绩从高到低排名,如果成绩并列则按语文从高到低排列, 如果语文成绩也相同,则按数学由高到低排列,如果数学成绩也相同,则按英语由高到低排列(不会出现总分相同&&语文相同&&数学相同&&英语相同情况)
做法:
由于每个学生有语文、数学和英语三门成绩,所以要单独构造一个Student类,里面包含语文、数学和英语和总成绩,然后建立一个学生姓名(String)到Student类的映射关系
package com.huawei.classroom.student.h19.q05;
import java.io.*;
import java.util.*;
public class StudentUtil {
private class Student{
String name;
int chineseScore;
int mathScore;
int engScore;
int totalScore;
public Student(String name) {
this.name = name;
}
public void updateScore(String subject, int score) {
if("语文".equals(subject)) {
this.chineseScore += score;
}else if("数学".equals(subject)) {
this.mathScore += score;
}else if("英语".equals(subject)) {
this.engScore += score;
}
totalScore += score;
}
}
public List<String> sort(String fileName){
Map<String,Student> stu = new HashMap<>(); //建立学生姓名和学生之间的关系
File file = new File(fileName);
try (BufferedReader reader = new BufferedReader(new FileReader(file))){
String line = "";
while((line = reader.readLine()) != null) {
String parts[] = line.split(",");
if(parts.length == 3) {
String name = parts[0].trim();
String subject = parts[1].trim();
int score = Integer.parseInt(parts[2].trim().substring(0,2));
Student student = stu.getOrDefault(name, new Student(name));
student.updateScore(subject, score);
stu.put(name, student); //相当于把更新后放到Map中
}
}
}catch(IOException e){
e.printStackTrace();
return null;
}
List<Student> students = new ArrayList<>(stu.values()); //把Map中所有value构造List
students.sort((a,b)->{
if(a.totalScore != b.totalScore) {
return Integer.compare(b.totalScore, a.totalScore);
}else if(a.chineseScore != b.chineseScore) {
return Integer.compare(b.chineseScore, a.chineseScore);
}else if(a.mathScore != a.mathScore) {
return Integer.compare(b.mathScore, a.mathScore);
}else {
return Integer.compare(b.engScore, a.engScore);
}
});
List<String> result = new ArrayList<>();
for(Student s : students) {
result.add(s.name);
}
return result;
}
}重点是排序方法,首先只有List能进行sort排序,所以先通过Map中的value值构造List列表,然后通过lambda函数从大到小进行排序(注意写法),最后返回结果。
h20
任务:
定义合适的类、接口,使得下面的代码编译并能正确运行
public static void main(String[] args) {
A a = new D();
C c = new D();
D d = new D();
System.out.println("pass 1");
B b = c;
System.out.println("pass 2");
a = d;
System.out.println("pass 3");
c=new E();
System.out.println("pass 4");
a=new A();
if (!(a instanceof B)) {
System.out.println("pass 5");
}
if (!(c instanceof A)) {
System.out.println("pass 6");
}
if (!(c instanceof D)) {
System.out.println("pass 7");
}
}做法:
总结:能new出来的都是class而不是interface,右边的都是子类或者子接口
根据上面的结论,可以判断A、D、E都是class;B、C是interface
由A a = new D()和C c = new D()可以判断D是A的子类,是C的子接口
由B b = c可以判断,C是B的子接口
由c=new E()可判断,E是C的子接口
代码:
public class A {
}
public interface B {
}
public interface C extends B{
}
public class D extends A implements C {
}
public class E implements C{
}注意,同类型的是extends;类继承接口是implements
h31
q02
任务:
list中每个元素存了一个字符串,请返回包含不同特殊字符 最多的字符串,所谓特殊字符在本题目中定义为如下9个字符:(~!@#$%^&*) 不包括括号, 不会出现并列的情况
做法:
这道题考察了map和set的使用,Map是用来表示每个字符串中特殊字符的个数,而set则是用来计算不同特殊字符的个数
public class Classq02 {
private Set<Character> charSet = new HashSet<>(Arrays.asList('~', '!', '@', '#', '$', '%', '^', '&', '*'));
public String findMaxDistinctCharWord(List<String> list) {
int i, max;
String ans = new String();
Map<String, Integer> map = new HashMap<>();
for (i = 0; i < list.size(); i++) {
String str = list.get(i);
if (!map.containsKey(str)) {
map.put(str, getDistinctCharCount(str));
}
}
max = 0;
Set<String> stringSet = map.keySet();
for (String str: stringSet) {
if (max < map.get(str)) {
max = map.get(str);
ans = str;
}
}
return ans;
}
public int getDistinctCharCount(String s) {
Set<Character> set = new HashSet<>();
char[] chars = s.toCharArray();
for (char cha : chars) {
if (charSet.contains(cha)) {
set.add(cha);
}
}
return set.size();
}
}q06
任务:
递归的计算一个目录子目录下包含的文件数量(不包括目录数量,仅仅包括文件数量)
做法:
要注意File对象有多个构造函数,这是其中的两个
File(String pathname);
File(File parent, String child);还要注意exists(),isDirectory(),list()函数的使用
public class Classq06 {
private int count = 0;
public Classq06() {
}
public int recursiveGetFileCount(String homeDir) {
//
File dir=new File(homeDir);
ListFiles(dir);
return count;
}
public void ListFiles(File dir) {
if (!dir.exists() || !dir.isDirectory()) { //dir不存在或dir不是目录
return;
}
String[] files = dir.list(); //里面存放着每个文件名
for (int i = 0; i < files.length; i++) {
File file = new File(dir, files[i]); //采用父级目录和文件名构造出路径
if (file.isFile()) {
count++;
} else {
ListFiles(file); // 对于子目录,进行递归调用
}
}
}
}q10
任务:
fileName文件中以 “商品名称,数量,总金额” 格式存放了若干购物流水 文件中可能有空行 也可能有 注释行(#开头) 商品名称 数量 总金额 前后可能有空格 请完成sortByAmount方法 按每种商品累积销售数量从高到低排序,如果出现累积销售数量相同的情况请按每种商品累积销售金额排序由高到低排序 请完成sortByMoney方法 按每种商品累积销售金额从高到低排序,如果出现累积销售金额相同的情况请按每种商品累积销售数量由高到低排序
做法:
此题比较复杂,建议多看几遍
首先构造了一个Item类,用来存放name,amount,money。注意这个类实现了Comparable接口
Comparable是排序接口;若一个类实现了Comparable接口,就意味着“该类支持排序”。可以使用Arrays.sort()对改类进行排序
在该类中定义了compareTo方法来进行数量的比较,定义了compareMTo方法来进行金钱的比较
在 Java 中,compareTo 方法的返回值定义了排序顺序: 返回 1 表示当前对象应该排在传入对象之后。 返回 -1 表示当前对象应该排在传入对象之前。 返回 0 表示两者相等。
Item.java类如下
public class Item implements Comparable{
private String name;
private int amount;
private int money;
public Item(String name, int amount, int money) {
this.name = name;
this.amount = amount;
this.money = money;
}
public String getName() {
return name;
}
public Item(String name, String amount, String money) {
this(name, Integer.valueOf(amount), Integer.valueOf(money));
}
public int compareTo(Object o) {
// TODO Auto-generated method stub
if (!(o instanceof Item)) {
return -1;
}
if (this.amount > ((Item) o).amount) {
return 1;
} else if (this.amount == ((Item) o).amount) { //升序排列
if (this.money > ((Item) o).money) {
return 1;
} else if (this.money == ((Item) o).money) {
return 0;
} else {
return -1;
}
} else {
return -1;
}
}
public int compareMTo(Object o) {
// TODO Auto-generated method stub
if (!(o instanceof Item)) {
return -1;
}
if (this.money > ((Item) o).money) {
return 1;
} else if (this.money == ((Item) o).money) { //升序排列
if (this.amount > ((Item) o).amount) {
return 1;
} else if (this.amount == ((Item) o).amount) {
return 0;
} else {
return -1;
}
} else {
return -1;
}
}
}Comparable重写compareTo,参数只有一个
Comparator重写compare,参数有两个
然后构造一个ItemComparator类用来比较两个Item的值
public class ItemComparator implements Comparator<Item> {
private final int order; //通过order是否为-1来决定到底是数值比较还是金钱比较
public ItemComparator(int order)
{
super();
this.order = order;
}
@Override
public int compare(Item i1, Item i2)
{
int result = -i1.compareTo(i2); //倒序排列
int resultM=-i1.compareMTo(i2);
if (this.order == -1) {
return result;
} else {
return resultM;
}
}
}classq10部分的主体有两个,一个是sortByAmount,一个是sortByMoney
注意在sort的参数为构造的Comparator
public List<String> sortByAmount(String fileName) {
//return sort(fileName);
int i;
List<String> result = new ArrayList<>();
List<Item> scoreLists = initScoreLists(fileName);
scoreLists.sort(new ItemComparator(-1));
for (i = 0; i < scoreLists.size(); i++) {
result.add(scoreLists.get(i).getName());
}
return result;
}public List<String> sortByMoney(String fileName) {
int i;
List<String> result = new ArrayList<>();
List<Item> scoreLists = initScoreLists(fileName);
scoreLists.sort(new ItemComparator(1));
for (i = 0; i < scoreLists.size(); i++) {
result.add(scoreLists.get(i).getName());
}
return result;
}其中比较关键的就是initScoreLists函数
public List<Item> initScoreLists(String filename) {
int i, j;
List<String[]> items = readLines(filename); //自己定义的逐行读文件函数,有模板
Set<String> nameSet = new HashSet<>();
List<Item> itemList = new ArrayList<>();
for (i = 0; i < items.size(); i++) {
String name = "";
int money = 0, amount = 0;
List<String> itemLine = new ArrayList<>(Arrays.asList("", "0", "0"));
line2list(items.get(i), itemLine); //将String[]转化为List<String>
name = itemLine.get(0);
if (nameSet.contains(name)) {
continue; //注意是双重循环,所以要continue
} else {
nameSet.add(name);
}
money += Integer.parseInt(itemLine.get(2));
amount += Integer.parseInt(itemLine.get(1));
for (j = i + 1; j < items.size(); j++) {
if (items.get(j)[0].equals(name)) {
line2list(items.get(j), itemLine);
money += Integer.parseInt(itemLine.get(2));
amount += Integer.parseInt(itemLine.get(1));
}
}
Item item = new Item(name, amount, money);
itemList.add(item);
}
return itemList;
}line2list函数如下:
public void line2list(String[] itemLine, List<String> itemList) {
String name = itemLine[0];
String amount = itemLine[1];
String money = itemLine[2];
itemList.set(0, name); //设定指定位置的值
itemList.set(1, amount);
itemList.set(2, money);
}逐行读文件函数模板如下:
private static List<String[]> readLines(String filename) {
String line = "";
Reader reader = null;
List<String[]> result = new ArrayList<>();
try {
reader = new FileReader(filename);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
if (reader == null) {
return null;
}
LineNumberReader lineReader = new LineNumberReader(reader);
try {
while (true) {
line = lineReader.readLine();
if (line == null) {
break;
}
if ("".equals(line) || line.charAt(0) == '#' || line.trim().length() == 0) {
continue;
}
result.add(line.replace(" ", "").split(","));
}
} catch (IOException e) {
e.printStackTrace();
}
return result;
}q11
任务1:
//第一问 完成Classq11.extractComment(String line)方法,具体要求见 Classq11.extractComment(String line)
String line="String str=\"he;/*test*/\";";
//这行的Java代码对应如下:
//String str="he;/*test*/";
//System.out.println(util.extractComment(line));
if("".equals(util.extractComment(line))) {
System.out.println("case 2 pass");
}
line="String str=\"he//\";//hi;";
//这行的Java代码对应如下:
//String str="he//";//hi;
//System.out.println(util.extractComment(line));
if("hi;".equals(util.extractComment(line))) {
System.out.println("case 3 pass");
}做法:
主要是掌握indexOf(str,beginIndex)函数和subString函数
注意"\""作为一个字符的字符串
public String extractComment(String line) {
// TODO Auto-generated constructor stub //{03e7c9a7b63b7c323243d92158ea746a}
int head = 0, tail = 0, primePos = 0;
int primePos1 = (line.indexOf("\"") == -1) ? 0 : line.indexOf("\"");
primePos = (primePos1 == 0) ? 0 : line.indexOf("\"", primePos1+1);
System.out.println(primePos);
System.out.println(primePos1);
if(line.indexOf("/*",primePos) != -1) {
head = line.indexOf("/*",primePos)+2;
tail = line.indexOf("*/",primePos)-1;
return line.substring(head,tail);
}else if(line.indexOf("//",primePos) != -1) {
head = line.indexOf("//",primePos)+2;
return line.substring(head);
}else {
return "";
}
}任务2:
第二问 导数表达式和导数值的计算 fx是只包含有一个自变量 x 是表达式,表达式中仅仅包含 加(+)、减(-)、乘(*)、除(/)、乘方(^ 且指数中不包含变量),请写一个函数计算fx的导数 例如:(x-8)^2/(x-2) x^3+x^2+1 6/(x+1)+7/(x+8) String fx = "x^2+6"; 第二问 1 请计算这个函数的导数表达式,表达式不唯一,例如 x+1 或者 1+x 或者 1 + x 都可以。 String dxe = util.getDxExp(fx); 第二问 2 请计算这个函数在指定x值的导数值并返回
做法:
???
h51
任务:
@param total 红包总金额,以元为单位,精确到分,系统测试的时候保证总金额至少够每人分得1分钱 @param personCount 分红包的总人数>0 @return 每个人分得的钱数 规则遵循微信分红包规则 例如: 要求 每人分得的钱数总和=total 每个人分得钱数必须是正数,且不能少于1分
做法:
完成这道题需要考虑两点
1.以元为单位,精确到分
这要求构造随机数的时候可以先整体*100,然后可以避免掉小数
2.至少够每人分得1分钱
这要求在生成随机数的时候先预先为每个人保留1分钱
public double[] getHongbao(double total,int personCount) {
double result[]=new double[personCount];
if(personCount <= 0) {
return result;
}
int totalCents = (int)Math.round(total*100);
Random random = new Random();
int remainCents = totalCents - personCount;
//这里只分配两个人的
for(int i = 0;i<personCount-1;i++) {
int randomCents = random.nextInt(remainCents+1); //[1,remainCents]
result[i] = (randomCents+1)/100.0; //这里包含了之前的1分钱
remainCents -= randomCents;
}
result[personCount-1] = (remainCents+1)/100.0;
return result;
}h52
任务:
将num进行质因数分解,将分解到的质因数放到Set里面返回
做法:
关键是考虑好算法,本题可以将大于等于2的数num从2开始依次遍历,如果找到一个质数因子,就把这个因子放到结果集中,并把num去除掉该因子,然后再从2开始依次遍历寻找(因为因子2可能不止一个)。
注意该算法不可能存在遍历到非质数的情况,因为非质数肯定由质数因子构成(如4可以分解为2*2)
public Set<Integer> decompose(int num) {
Set<Integer> res = new HashSet<>();
if(num <= 0) {
return null;
}else if(num == 1) {
res.add(1);
}else {
int i = 2;
while(i <= num) {
if(num % i == 0) {
res.add(i);
num = num/i; //把i这个因数去掉,剩下的因子构成num
i = 2; //i每次从2开始
}else {
i++; //不可能出现不是质数的情况,因为因子已经从小到大考虑过了
}
}
}
return res;
}h53
任务:
1对兔子出生以后经过180天可以生出一窝(2对)兔子,以后每隔90天繁殖一次生出一窝(2对)兔子 每对兔子的寿命是700天 @param startCount 第0天 开始的时候初生的兔子对数 @param days 经过的天份数 @return 目前系统中存活的兔子的对数
做法:
首先要构造一个Rabbit类来存放每个兔子的年龄
整体框架是两层循环,外层是考虑从第0天到第days天,内层是考虑每一天所有的兔子年龄+1,以及它们是否繁殖,是否死亡
public int getLivingRabbit(int startCount,int days) {
List<Rabbit> rabbits = new ArrayList<>();
for(int i = 0;i<startCount;i++) {
rabbits.add(new Rabbit(0));
}
for(int day = 1; day <= days ;day++) {
int initialSize = rabbits.size();
for(int i = 0; i < initialSize;i++) {
Rabbit r = rabbits.get(i);
r.age++;
if(r.age >= 180 && (r.age - 180) % 90 == 0) {
rabbits.add(new Rabbit(0));
rabbits.add(new Rabbit(0));
}
if(r.age > 700) {
rabbits.remove(i);
i--;
initialSize--;
}
}
}
return rabbits.size();
}h54
任务:
判断一个口令是否是一个复杂度合法的口令,复杂度合法的口令有如下要求: 1 长度>=8 2 最少包含一个数字 3 最少包含一个小写英文字母 4 虽少包含一个大写英文字母 5 最少包含一个特殊字符 特殊字符定义为 ~!@#$%^&*()_+
做法:
注意本题不是考察正则表达式,所以考虑用字典的方式,把2,3,4,5这四个条件对应的出现次数存起来,如果出现的次数为0,那么口令不符合要求
public boolean isValidPassword(String password){
Map<String, Integer> res = new HashMap<>();
if(password.length() < 8) {
return false;
}
res.put("number", 0);
res.put("lowerCase", 0);
res.put("upperCase",0);
res.put("special", 0);
String flag = new String("~!@#$%^&*()_+");
for(int i = 0; i< password.length(); i++) {
char c = password.charAt(i);
if(c > '0' && c < '9') {
res.put("number", res.getOrDefault("number", 0)+1);
}else if(c > 'a' && c < 'z') {
res.put("lowerCase", res.getOrDefault("lowerCase", 0)+1);
}else if(c > 'A' && c < 'Z') {
res.put("upperCase", res.getOrDefault("upperCase", 0)+1);
}else if(flag.contains(c + "")) { //将字符转为字符串
res.put("special", res.getOrDefault("special", 0)+1);
}
}
boolean isValid = true;
for(Map.Entry<String, Integer> entry : res.entrySet()) {
if(entry.getValue() == 0) {
isValid = false;
}
}
return isValid;
}h55
任务:
用计算机来证明 为什么说李白是浪漫主义诗人 杜甫是现实主义诗人
分析不同诗人使用一些汉字时候的特点
1 分析不同诗人使用一个汉字的时候,将这些汉字组成什么词汇使用在诗句里面
2 按这些词汇出现的频率高低排序;
3 只要是两个汉字连起来就视为一个词。
@param pathFilename 包含诗歌内容的源文件 @param chars 需要统计的字 以半角分号分割
做法:
将读到的字符串拆为一个词一个词的,然后判断是否是汉字,是否包含chars出现的内容
public void analysis(String pathFilename,String chars) {
Map<String, Integer> res = new HashMap<>();
File f = new File(pathFilename);
String line = "";
try {
BufferedReader reader = new BufferedReader(new FileReader(f));
while((line = reader.readLine()) != null) {
for(int i = 0;i<line.length()-1;i++) {
String word = line.substring(i,i+2);
if(word.matches("[\\u4e00-\\u9fa5]{2}") && (chars.contains(word.substring(0, 1)) || chars.contains(word.substring(1, 2)))) { //确保是两个汉字
res.put(word, res.getOrDefault(word, 0)+1);
}
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
int maxCount = 0;
for(Map.Entry<String, Integer> entry: res.entrySet()) {
if(maxCount < entry.getValue()) {
maxCount = entry.getValue();
}
}
int counter = 0;
for(int i = maxCount;i>0;i--) {
for(Map.Entry<String, Integer> entry : res.entrySet()) {
if(entry.getValue() == i) {
System.out.println(entry.getKey() + " "+ entry.getValue());
counter++; //只有打印出来了,计数器才+1
if(counter==10) {
break;
}
}
}
if(counter==10) { //防止打印出排名并列的从而超过10个
break;
}
}
}h56
任务:
将homeDir 目录下(包括子目录)所有的文本文件(扩展名为.txt,扩展名不是.txt的文件不要动,扩展名区分大小写) 文件中,orgStr替换为 targetStr 所有文本文件均为UTF-8编码 例如将某个目录中所有文本文件中的 南开大学 替换为 天津大学 @param homeDir @param orgStr @param targetStr
做法:
本题考察了两点,一个是递归的读文件,另外一个是BufferedReader和BufferedWriter的使用
经典递归读文件的方法
public void listFiles(File dir) {
if(!dir.exists() || !dir.isDirectory()) {
return;
}
String[] files = dir.list();
for(int i = 0; i< files.length ;i++) {
File f = new File(dir,files[i]); //这里要加上根目录
if(f.isFile() && files[i].endsWith(".txt")) {
res.add(f);
}else {
listFiles(f);
}
}
}然后注意BufferedReader的构造,FileInputStream->InputStreamReader->BufferedReader
BufferedWriter的构造,FileOutputStream->OutputStreamWriter->BufferedWriter
通过增加一个firstLine布尔值来判断是不是第一行,涉及到换行问题
public void replaceTxtFileContent(String homeDir,String orgStr,String targetStr) {
File dir = new File(homeDir);
listFiles(dir);
for(int i = 0;i<res.size();i++) {
File f = res.get(i);
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(f),"UTF-8")); //加入UTF-8防止乱码
StringBuilder contents = new StringBuilder();
String line = "";
boolean firstLine = true;
while((line = reader.readLine()) != null) { //把所有内容都读出来然后替换
if(firstLine) {
contents.append(line.replace(orgStr, targetStr));
firstLine = false;
}else {
contents.append(System.lineSeparator()).append(line.replace(orgStr, targetStr));
}
}
reader.close();
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(f),"UTF-8"));
writer.write(contents.toString()); //这里是覆盖写
writer.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}h57
任务:
统计一个目录下所有文件大小的加和
做法:
还是对经典读文件的考察,注意file.length()是返回文件的大小
public static long sizeSum = 0;
public long recursiveCalcFileSize(String homeDir) {
File dir = new File(homeDir);
listFiles(dir);
return sizeSum;
}
public void listFiles(File dir) {
if(!dir.exists() || !dir.isDirectory()) {
return;
}
String[] files = dir.list();
for(int i = 0;i<files.length;i++) {
File f = new File(dir, files[i]);
if(f.isFile()) {
sizeSum += f.length(); //返回文件的大小
}else {
listFiles(f);
}
}
}h58
任务:
fileName是一个投票的明细记录,里面逐行存放了 投票的时间(yyyy-MM-dd HH:mm:ss 格式) +\t+投票的微信ID+\t+候选人 存放按时间递增(但是可能出现同一秒出现若干条记录的情况) 现在需要完成投票统计的过程,具体要求如下: 1个微信ID 1分钟内 最多投1票 多余的票数无效 1个微信ID 10分钟内 最多只能投5票 多余的票无效 其中微信ID不固定,候选人姓名不固定 测试的时候要求10万行记录处理时间不超过3秒 @param fileName @return 返回一个map,其中key是候选人名字,value的票数
做法:
本题较为复杂,主要是去除不合法记录的算法需要理解
首先创建两个类,一个Record用来记录投票的时间、投票id,投选人,增加一个boolean值判断该记录是否合法;另外一个Voter类用来记录投票id,和每个投票id的Record(List列表)
注意Record实现Comparator,重写compareTo,比较时间的大小,按时间从小到大进行排序(虽然本题中已经排好)
Voter只要id相同即可认为相同,所以Voter实现Serializable,重写hashCode和equals方法,每个Voter对象的hashCode值为对应的id的hashCode的值,只要id的值相同则可认为是一个Voter
接下来是Voter类里面的去除不合法记录的算法
为了保证10分钟内不能有同一投票者投票超过5次,所以先构造一个buffer数组,放入5个元素进去,用next变量来记录当前走到records中的位置,定义一个循环,只要next<records.size(),那么先判断这个buffer内是否有不满足1分钟之内只能投一票的要求,注意每次都要更新i值和oneMinLater的值;然后判断buffer内是否有两个记录超过10min,如果有的话,移除第一个元素,添加records中的下一个元素(相当于buffer右移),注意这里还要针对没有添加元素成功的情况正确的更新i的值,此处和1分钟那里不同的原因在于,1分钟是比较buffer中两两之间的时间间隔,而这里每次都是和buffer第一个元素比较;最后,如果buffer外下一条记录在10min之内,直接设置该记录不合法即可。
为了保证不陷入死循环,每次判断完上述三个条件后,都需要移除第一个元素,添加下一个元素,即实现buffer的右移
这里还要进行最后一次判断1min,以为还可能存在最后一条记录不符合规范,如120min,120.5min,而这个120.5min恰好是最后一个记录,由于next == records.size(),所以单独判断一次,这也是最后一次判断。10min的不用判断的原因是已经在上面的循环中判断过了
最后在VoterRecord.java中先通过写一个readLine函数读取所有的记录,根据所有的记录Records读出所有的id存入到一个Set中,根据Set中的所有元素构造一个List<Voter>。再用一个双重循环,遍历所有Voter,对每个Voter遍历所有Records,如果id相同则把该条记录放入到Voter中。最后遍历Voter,对每个Voter都去除不合法记录,把他的所有投票结果加入到Map<候选人的名字,票数>中
代码如下
Record.java
package com.huawei.classroom.student.h58;
import java.text.*;
import java.util.Date;
public class Record implements Comparable{
private Date time;
private String id;
private String name; //候选人的名字
private boolean isValid;
public Record(String t, String id, String name) {
DateFormat fmt = new SimpleDateFormat("yyyy-MM-DD HH:mm:ss");
try {
this.time = fmt.parse(t);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
this.id = id;
this.name = name;
this.isValid = true;
}
public Date getDate() { //由于getTime是系统的函数,这里改为getDate
return this.time;
}
public String getId() {
return this.id;
}
public String getName() {
return this.name;
}
public void setValid(boolean flag) {
this.isValid = flag;
}
public boolean getIsValid() {
return this.isValid;
}
@Override
public int compareTo(Object o) {
if(! (o instanceof Record)) {
return -1;
}
Record that = (Record)o;
return this.time.compareTo(that.time); //根据时间顺序排名记录
}
}Voter.java
package com.huawei.classroom.student.h58;
import java.io.Serializable;
import java.util.*;
public class Voter implements Serializable{
private String id; //不同投票者的区别是id不同
private List<Record> records = new ArrayList<>();
public Voter(String id) {
this.id = id;
}
public void addRecord(Record record) {
records.add(record);
}
public String getId() {
return this.id;
}
public List<Record> getRecords(){
return this.records;
}
public void removeInvalidRecords() {
records.sort(Record:: compareTo);
List<Record> buffer = new LinkedList<>();
int next = 0;
for(int i = 0; i < Math.min(5, records.size());i++) {
buffer.add(records.get(next++));
}
while(next < records.size()){
Date curTime = buffer.get(0).getDate();
Date oneMinLater = new Date(curTime.getTime()+60000);
Date tenMinLater = new Date(curTime.getTime()+600000);
for(int i = 1; i < buffer.size() ;i++) {
if(buffer.get(i).getDate().compareTo(oneMinLater) < 0) { //在1min之内
buffer.get(i).setValid(false);
buffer.remove(i--);
if(next < records.size()) {
buffer.add(records.get(next++));
}
}
oneMinLater = new Date(buffer.get(i).getDate().getTime()+60000);
}
for(int i = 1 ;i <buffer.size();i++) {
if(buffer.get(i).getDate().compareTo(tenMinLater) >= 0) { //在10min之后
buffer.remove(0);
if(next < records.size()) {
buffer.add(records.get(next++));
}
if(buffer.size() != 5) { //针对没有添加元素成功的情况
i = buffer.size()-2;
}else {
i--;
}
tenMinLater = new Date(buffer.get(0).getDate().getTime()+600000);
}
}
while(next < records.size()) {
if(records.get(next).getDate().compareTo(tenMinLater) < 0) { //如果buffer外下一条记录在10min之内
records.get(next++).setValid(false);
}else {
break;
}
}
if(next < records.size()) {
buffer.remove(0);
buffer.add(records.get(next++));
}
}
//再次也是最后一次判断,防止最后一个元素不符合规范
if(buffer.size() > 1) {
Date curTime = buffer.get(0).getDate();
Date oneMinLater = new Date(curTime.getTime()+60000);
Date tenMinLater = new Date(curTime.getTime()+600000);
for(int i = 1; i < buffer.size() ;i++) {
if(buffer.get(i).getDate().compareTo(oneMinLater) < 0) { //在1min之内
buffer.get(i).setValid(false);
buffer.remove(i--);
}
oneMinLater = new Date(buffer.get(i).getDate().getTime()+60000);
}
}
}
@Override
public int hashCode() {
return id.hashCode();
}
@Override
public boolean equals(Object o) {
if(!(o instanceof Voter)) {
return false;
}
Voter that = (Voter) o;
return this.id.equals(that.id);
}
}VoterRecord.java
package com.huawei.classroom.student.h58;
import java.util.*;
import java.io.*;
public class VoteRecord {
/**
* fileName是一个投票的明细记录,里面逐行存放了 投票的时间(yyyy-MM-dd HH:mm:ss 格式) +\t+投票的微信ID+\t+候选人
* 存放按时间递增(但是可能出现同一秒出现若干条记录的情况)
* 现在需要完成投票统计的过程,具体要求如下:
* 1个微信ID 1分钟内 最多投1票 多余的票数无效
* 1个微信ID 10分钟内 最多只能投5票 多余的票无效
* 其中微信ID不固定,候选人姓名不固定
* 测试的时候要求10万行记录处理时间不超过3秒
* @param fileName
* @return 返回一个map,其中key是候选人名字,value的票数
*/
public List<Voter> voters = new ArrayList<>();
public Map<String,Integer> calcRecording(String fileName){
Map<String, Integer> res = new HashMap<>();
List<Record> allRecords = new ArrayList<>();
Set<String> voterIds = new HashSet<>();
allRecords = readLines(fileName);
for(Record rec : allRecords) {
voterIds.add(rec.getId());
}
for(String voterId : voterIds) {
Voter vo = new Voter(voterId);
voters.add(vo);
}
for(Voter v : voters) {
for(Record rec : allRecords) {
if(rec.getId().equals(v.getId())) {
v.addRecord(rec);
}
}
}
for(Voter v : voters) {
v.removeInvalidRecords();
for(Record r : v.getRecords()) {
if(r.getIsValid()) {
res.put(r.getName(), res.getOrDefault(r.getName(), 0)+1);
}
}
}
return res;
}
public List<Record> readLines(String path) {
File f = new File(path);
List<Record> res1 = new ArrayList<>();
try {
BufferedReader reader = new BufferedReader(new FileReader(f));
String line = "";
while((line = reader.readLine()) != null) {
String[] elements = line.split("\t");
String time = elements[0];
String id = elements[1];
String name = elements[2];
Record record = new Record(time,id,name);
res1.add(record);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return res1;
}
}测试Tips:可以先自己构造一个小的测试用例进行测试
h59
任务:
本文件中存放了若干的化学反应方程式(总数量不会超过1000个) 某个文本本文件中存放了一系列的化学反应 #表示注释 化学反应以 = 分为了左侧和右侧;不同化合物之间至少有 一个空格 A + B = C + D 意味着体系中如果有了 A B 就可以生成C D,同样如果有C D 也可以生成 A B 所有反应 反应物前系数均为 1 根据一个体系中初始化合物 ,最后可能都存在什么化合物
做法:
本题关键是要构造一个双映射关系,即可以通过反应物得知生成物,也可以通过生成物得到反应物
由于一个物质存在只能存在一种,所以用Set来记录反应物和生成物
然后根据已有的初始物质,遍历每一条反应,得到所有的物质
注意containsAll()和addAll()的用法
public class Reaction {
private Set<String> reactant = new HashSet<>();
private Set<String> product = new HashSet<>();
public Reaction(Set<String> reactant, Set<String> product) {
this.reactant = reactant;
this.product = product;
}
public Set<String> getReactant(){
return reactant;
}
public Set<String> getProduct(){
return product;
}
}public Set<String> findAllComponents(String reactionFile,Set<String> initComponents){
Set<String> result = new HashSet<>(initComponents); //初始化直接根据initComponents构建result
List<Reaction> reactions = readLines(reactionFile);
int addCount = initComponents.size();
while(addCount != 0) {
addCount = 0;
for(Reaction rea : reactions) {
if(result.containsAll(rea.getReactant()) && result.addAll(rea.getProduct())) {
addCount++;
}else if(result.containsAll(rea.getProduct()) && result.addAll((rea.getReactant()))){
addCount++;
}
}
}
return result;
}
public List<Reaction> readLines(String reactionFile){
List<Reaction> res = new ArrayList<>();
File f = new File(reactionFile);
try {
BufferedReader reader = new BufferedReader(new FileReader(f));
String line = "";
while((line = reader.readLine()) != null) {
if(line.startsWith("#") || line.trim().length() == 0) {
continue;
}
String[] reaction = line.split("=");
String left = reaction[0];
String right = reaction[1];
String[] lefts = left.split("\\ \\+\\ "); //这里是正则表达式,如果只有一个反应物则返回值不变(不分割)
Set<String> leftSet = new HashSet<>();
for(String ele : lefts) {
leftSet.add(ele.trim());
}
String[] rights = right.split("\\ \\+\\ ");
Set<String> rightSet = new HashSet<>();
for(String ele : rights) {
rightSet.add(ele.trim());
}
Reaction rea = new Reaction(leftSet,rightSet);
res.add(rea);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return res;
}h60
任务:
在ChatServer,ChatClient中增加适当代码,并增加适当的类,完成一个简单的聊天室 user.txt中存放了所有用户的用户名和口令 用\t分割
做法:
首先要搞清楚服务器和客户端两者的代码模版,参考ch10.MyserverSocketV3.java、ch10.MyClientSocketV3.java和ch10.ServerThread.java
我的做法和上面的模板略有不同,我是在ChatServer里面写了一个内部类ClientHandler,实现Runnerable接口,然后再startListen中每次都用ClientHandler作为构造函数的参数新建线程并启动,注意这个方法每次调用startListen时,都要用lambda函数来启动一个新的线程(具体见代码)
所以,整体的框架是ChatServer类中有一个内部类ClientHandler,在ChatServer中构建一个集合来存储所有的ClientHandler(便于读写操作和广播操作),ChatServer中实现功能的主要部分,包括登录用户名和口令的验证等等。ChatClient可以看做是一个专门用来接收in.readLine()和发送out.write()的工具
然后是实现思路的问题:
1.如何实现客户端的登录和退出以及读写操作?
我的方法是每当客户端要完成一个动作时都会先写指令给服务器,服务器得到指令后进行相应的判断和操作,最后返回给客户端相应的内容
2.如何实现只有登录以后才可以读到,否则返回null
这个可以在服务器中,具体来讲是ClientHandler定义一个boolean值loggedIn来判断是否登录成功,如果没有则不能进行相应的读写操作
3.如何得到聊天室里面所有的发言(包括自己的)
在ChatServer中构建一个消息列表,为每个ClientHandler分配一个消息索引指针,注意这个列表是同步的并且要加锁。每当客户端发消息时,都把消息存储到这个列表中;当客户端读消息的时候,根据自己的消息索引指针来读取相应的内容。
我的做法还有相应的扩展,即新增了一个broadcastMessage方法用来广播系统消息(如“xxx has joined the chat”),区分系统消息和对话消息可以在消息前面加“SYSTEM”或“MESSAGE”
ChatServer.java
package com.huawei.classroom.student.h60;
import java.io.*;
import java.net.*;
import java.util.*;
public class ChatServer {
/**
* 初始化 , 根据情况适当抛出异常
* @param port
* @param passwordFilename 所有用户的用户名 口令
*/
private static boolean flag = true;
private int port;
private String passwordFilename;
private Map<String,String> userDetails;
private Set<ClientHandler> clientHandlers; //保存所有登录的用户
private List<String> messageList;
public ChatServer (int port, String passwordFilename) throws IOException {
this.port = port;
this.passwordFilename = passwordFilename;
userDetails = new HashMap<>();
clientHandlers = new HashSet<>();
messageList = Collections.synchronizedList(new ArrayList<>());
loadUsersDetails();
}
public void loadUsersDetails() {
File f = new File(passwordFilename);
try {
BufferedReader reader = new BufferedReader(new FileReader(f));
String line = "";
while((line = reader.readLine()) != null) {
String[] detail = line.split("\t");
if(detail.length == 2) {
userDetails.put(detail[0], detail[1]);
}
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 根据情况适当抛出异常
* 开始监听
*/
public void startListen( ) {
new Thread(()->{
ServerSocket server = null;
try {
server = new ServerSocket(port);
System.out.println("chat server listen on port:" + port + " ok!");
while(flag) {
Socket socket = server.accept();
ClientHandler clientHandler = new ClientHandler(socket);
clientHandlers.add(clientHandler);
new Thread(clientHandler).start();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}).start();
}
private class ClientHandler implements Runnable {
private Socket clientSocket;
private PrintWriter out;
private BufferedReader in;
private String userName;
private boolean loggedIn; //判断是否已经登录
private int messageIndex;
public ClientHandler(Socket clientSocket) {
this.clientSocket = clientSocket;
loggedIn = false;
messageIndex = 0;
}
@Override
public void run() {
try {
out = new PrintWriter(clientSocket.getOutputStream(), true);
in = new BufferedReader(new InputStreamReader(clientSocket.getInputStream()));
String inputLine;
while ((inputLine = in.readLine()) != null) {
String[] parts = inputLine.split(" ", 2);
String command = parts[0];
if (command.equals("LOGIN")) {
String[] credentials = parts[1].split(" ");
if (credentials.length == 2 && authenticate(credentials[0], credentials[1])) {
userName = credentials[0];
loggedIn = true;
out.println("LOGIN SUCCESS");
broadcastMessage("SYSTEM "+ userName + " has joined the chat");
} else {
out.println("LOGIN FAILURE");
}
} else if (command.equals("LOGOUT")) {
if (userName != null) {
broadcastMessage("SYSTEM "+ userName + " has left the chat");
clientHandlers.remove(this);
loggedIn = false;
break;
}
} else if (command.equals("SPEAK")) {
if(loggedIn) {
if (userName != null) {
String message = "MESSAGE "+ parts[1]; //这里不用写是谁说的(根据Test要求)
synchronized(messageList) {
messageList.add(message);
}
//broadcastMessage(message); //如果还广播的话,就会出现四个MESSAGE信息
}
}else {
out.println("You need to login first!");
}
} else if (command.equals("READ")) {
if(loggedIn) {
String message;
synchronized(messageList) {
if(messageIndex < messageList.size()) {
out.println(messageList.get(messageIndex));
messageIndex++;
}else {
out.println("READ null");
}
}
}else {
out.println("You need to login first!");
}
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (clientSocket != null) {
clientSocket.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private boolean authenticate(String userName, String password) {
return password.equals(userDetails.get(userName));
}
private void broadcastMessage(String message) {
for (ClientHandler handler : clientHandlers) {
if(handler.loggedIn) {
handler.out.println(message);
}
}
}
}
}ChatClient.java
package com.huawei.classroom.student.h60;
import java.io.*;
import java.net.*;
public class ChatClient {
private String ip;
private int port;
private Socket socket;
private PrintWriter out;
private BufferedReader in;
/**
* 根据情况适当抛出异常
* @param ip
* @param port
*/
public ChatClient (String ip, int port) {
this.ip = ip;
this.port = port;
}
/**
* 登录,成功返回true,否则返回false,根据情况适当抛出异常
*
* @param userName
* @param password
* @return
*/
public boolean login(String userName,String password) {
try {
socket = new Socket(ip, port);
out = new PrintWriter(socket.getOutputStream(), true);
in = new BufferedReader(new InputStreamReader(socket.getInputStream()));
out.println("LOGIN "+userName + " "+password);
String response = in.readLine();
return response.equals("LOGIN SUCCESS");
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
}
}
/**
* 退出,根据情况适当抛出异常
*/
public void logout() {
if(socket != null && out != null) {
out.println("LOGOUT");
closeConnection();
}
}
/**
* 发言, 只有登录以后才能发言, 根据情况适当抛出异常
* 如果没有登录 抛出异常
*
* @param str
*/
public void speak(String str) {
if(out != null) {
out.println("SPEAK "+ str);
}
}
/**
* 读取聊天室目前的发言,根据情况适当抛出异常
* 只有登录以后才可以读到,否则返回null
* 得到聊天室里面所有的发言(包括自己的),如果此时没有发言则立刻返回null,否则每次调用read的时候按队的方式返回一个句话
*/
public String read() {
if(out != null) {
out.println("READ");
try {
String response;
while ((response = in.readLine()) != null) {
if (response.startsWith("MESSAGE ")) {
return response.substring(8);
}else if (response.startsWith("READ null")) {
return null;
}
if(response.equals("You need to login first!")) {
break;
}
// 如果是系统消息,继续读取
}
} catch (IOException e) {
// TODO Auto-generated catch block
//e.printStackTrace();
return null;
}
}
return null;
}
private void closeConnection() {
try {
if(socket != null) {
socket.close();
}
if(out != null) {
out.close();
}
if(in != null) {
in.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
评论