

一、协议设计
具体要求:
当服务器在等待一个客户端发送下一个请求时,能够同时处理来自其它客户端的请求,使服务器能够同时处理多个并发的客户端。
注意:
将服务器能够支持的最大连接数设置为 1024,这是操作系统可用文件描述符数量的最大值。
客户端可能会“暂停”(即请求发送了一半突然暂停)或出错,但这些问题不应对其他并发用户产生不良影响。也就是说,如果一个客户端只发送了请求的一半就停止了,那么服务端应继续为另一个客户端提供服务。
只能通过 select()方法实现并发,禁止使用多线程。
(一)协议头部
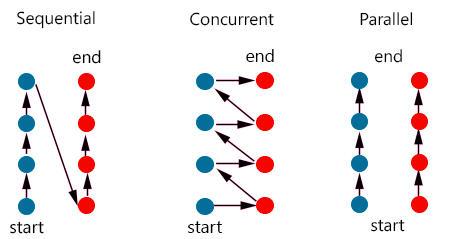
在讨论并发的概念时,常常会提到另一个相关概念——并行。以下是对这两个概念的区分:
并发(Concurrency): 并发是指在不同时间点将任务交给处理器处理。在某一时刻,多个任务可能不会同时运行,但它们会在不同时间片轮流执行。
并行(Parallelism): 并行则是将每个任务分配给独立的处理器进行处理。在某一时刻,多个任务可以同时运行。
并发和并行有显著的区别。并行是在不同的物理处理器上同时执行不同的代码片段,其关键是同时完成多个任务。而并发则是同时管理多个任务,这些任务可能在执行过程中被暂停,以便处理其他任务。
在现代服务器上,实现并发主要有两种方法:多线程同步阻塞和 I/O 多路复用。
如果服务器不做特别处理,每次只能处理一个连接。新的连接必须等待当前连接结束才能建立,这就是最初的同步阻塞方法。这种方式一次只能连接一对服务器和客户端。
为了提高处理效率,多线程同步阻塞方法应运而生。每次 accept 接受一个连接,就创建一个线程来处理该连接,这样就可以同时处理多个连接,这是经典的多线程同步阻塞方法。
然而,多线程同步阻塞并不理想,会导致资源浪费。每个 TCP 连接需要一个线程,10k 个连接需要 10k 个线程。然而,大部分连接并不活跃,即便需要处理业务逻辑,也可以快速返回结果,大部分时间都在 I/O 阻塞或等待网络响应。这使得创建和管理大量线程非常耗费资源,线程切换也极其耗费 CPU。最终,CPU 处理实际业务的时间少,大部分资源浪费在线程切换上。
I/O 多路复用方法则不同,它将阻塞的 socket 暂时放置一边,处理其他事情,从而避免资源浪费,这是非阻塞 I/O 的核心概念。
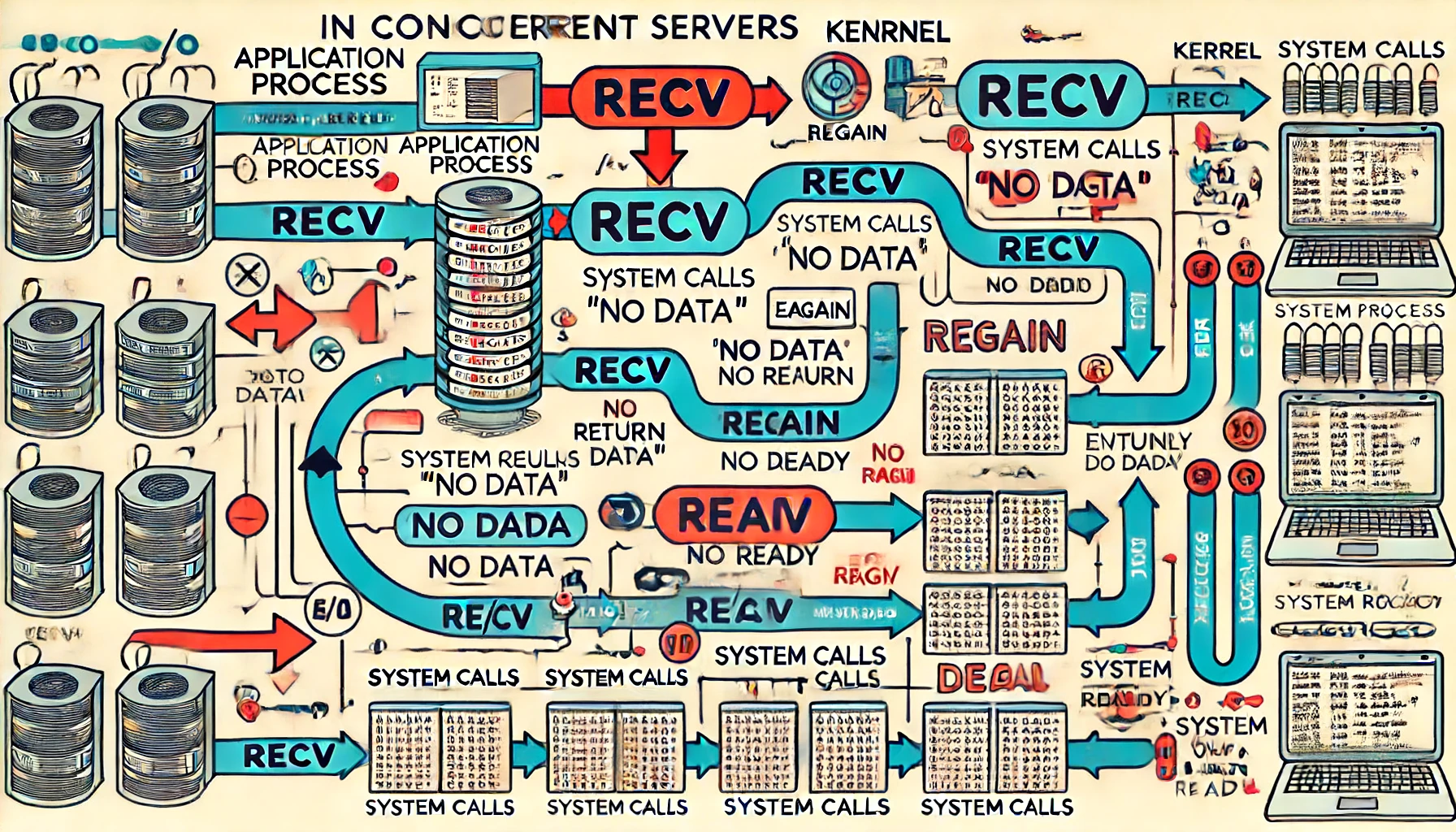
上图展示了调用 recv 时的情况。当用户进程发出 read 操作时,如果内核中的数据尚未准备好,系统不会阻塞用户进程,而是立即返回一个错误。用户进程不需要等待,而是立即知道数据尚未准备好,于是可以再次发送 read 操作。一旦内核中的数据准备好,再次接收到用户进程的系统调用,数据会立刻被拷贝到用户内存,然后返回。
I/O 多路复用的原理是不断检查多个 socket,当某个 socket 数据准备好时立即返回,否则整个进程继续阻塞。这样,一个进程可以在不耗费大量资源的情况下处理多个连接。这种轮询操作由内核态完成,从而减少内核态和用户态之间的切换。
(二)协议规则
具体实现的流程如下:
1)主进程采用 I/O 多路复用技术来监控多个 socket 资源。
2)当客户端尝试连接时,服务端会接受连接请求,并将其加入到监控列表中。
3)客户端与服务端之间的通信也会触发 I/O 复用函数返回。
4)服务端在循环中同时处理新的连接请求和已有连接的业务请求。
(三)主要数据结构
在本次第四周的 socket 实验中,我们引入了一个名为 fdclient[] 的数组数据结构,用作用户池。这个数组的定义和初始化如下所示:
int fdclient[1024] = {0};数组的大小设置为 1024,这是因为实验指导书中提到最大连接用户数为 1024。为了管理和操作这个用户池,我们使用了一个辅助索引 fdptr,其定义如下:
int fdptr = 1024;fdptr 是一个整数变量,用来记录当前处理的用户在用户池中的位置。在处理用户连接的循环中,fdptr 会持续遍历 fdclient[] 数组中的所有用户,从而确保每个用户都能被正确处理和管理。
进一步解释:
用户池 (
fdclient[]): 这个数组用于存储每个连接的文件描述符。文件描述符是系统为每个连接分配的唯一标识符,用于跟踪和管理活动连接。辅助索引 (
fdptr):fdptr是一个指针,指向当前正在处理的用户在fdclient[]数组中的位置。每次新的连接或需要处理现有连接时,fdptr会更新以指向下一个用户,从而在循环中遍历所有连接。循环处理: 在服务器运行过程中,会进入一个循环,使用
fdptr遍历fdclient[]数组中的每个用户,处理他们的连接请求和数据传输。这种方法确保了服务器能够高效地管理多个并发连接。
(四)相关算法
本周的实验任务是确保服务器能够在等待一个客户端发送下一个请求的同时,处理来自其他客户端的请求,从而实现对多个并发客户端的支持。为实现这一目标,我们将使用 select 函数。
select 是一个阻塞调用函数,允许我们监听多个文件描述符(socket)的状态,并在其中某个变为可读、可写或发生异常时返回。这样,服务器可以同时处理多个客户端连接,而无需为每个连接创建一个线程。
select 函数原型:
int select(
int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
const struct timeval *timeout
);nfds:这个参数在现代实现中已被忽略,主要用于兼容性目的。
readfds:指向一组等待可读性检查的文件描述符的集合。
writefds:指向一组等待可写性检查的文件描述符的集合。
exceptfds:指向一组等待异常状态检查的文件描述符的集合。
timeout:指定
select等待的最长时间,可以是 NULL 表示无限期阻塞。
fd_set 的理解:
fd_set 是一个文件描述符集合,用于指定需要监听的文件描述符。可以将 fd_set 视为一个位数组,其中每一位表示一个文件描述符的状态。假设 fd_set 的大小为 1 字节,则可以表示最多 8 个文件描述符。如果 sizeof(fd_set) 为 512 字节,则可以表示 512 * 8 = 4096 个文件描述符。
使用 select 的步骤:
初始化
fd_set:使用FD_ZERO宏清空集合,然后使用FD_SET宏添加需要监听的文件描述符。调用
select:传递文件描述符集合以及超时时间,select将阻塞直到其中一个文件描述符变为可读、可写或发生异常,或者超时。处理返回结果:使用
FD_ISSET宏检查哪个文件描述符准备好,并进行相应处理。
select 的性能注意事项:
内核态和用户态的拷贝开销:每次调用
select,都需要将文件描述符集合从用户态拷贝到内核态,这在文件描述符数量较多时会产生较大的开销。线性扫描:内核需要线性扫描整个
fd_set集合,因此随着监控文件描述符数量的增加,I/O 性能会线性下降。
算法内容
初始化和创建套接字
创建服务器套接字并设置为非阻塞模式。
绑定服务器套接字到指定的地址和端口,并开始监听连接请求。
并发处理
使用
select()方法监控多个文件描述符,等待它们变为可读或可写状态。当一个新客户端连接时,接受连接并将客户端套接字设置为非阻塞模式。
将客户端套接字添加到文件描述符集合中,以便
select()方法监控它们。
处理客户端请求
当客户端发送数据时,接收并处理请求,根据 HTTP 方法(GET、HEAD、POST)执行相应的操作。
如果接收到的请求不完整或出现错误,关闭客户端连接并从文件描述符集合中移除该客户端。
向客户端发送响应,包括错误信息(如 400、404、501 等)。
日志记录
在处理请求和发送响应时,记录每个请求的详细信息,包括请求的类型、来源 IP、时间等。
在出现错误时,记录错误信息和相关的详细信息。
伪代码
函数 main()
初始化服务器套接字
将套接字绑定到端口 9999
监听套接字
初始化 fd 集合用于 select()
将服务器套接字添加到 fd 集合
循环
复制 fd 集合以供 select() 使用
调用 select() 监视套接字
如果服务器套接字有新连接
处理新连接()
处理现有连接()
关闭服务器套接字
函数 处理新连接()
接受新连接
将客户端套接字添加到 fd 集合
函数 处理现有连接()
遍历 fd 集合中的每个套接字
如果套接字有数据可读
处理客户端()
函数 处理客户端()
当客户端有数据可读
从客户端读取数据
解析 HTTP 请求
处理请求()
将响应发送回客户端
如果必要,关闭客户端连接
函数 处理请求()
如果请求为空
发送 400 错误响应
记录错误日志
否则如果请求有效
检查 HTTP 版本
如果版本不支持
发送 505 错误响应
记录错误日志
否则
调用 use_method() 处理请求
否则
发送 501 错误响应
记录错误日志
函数 关闭客户端()
从 fd 集合中移除客户端套接字
关闭客户端套接字
函数 发送错误响应()
构造错误响应
将响应发送到客户端
四、实验结果分析与测试
ApacheBench(简称 ab)是 Apache 服务器附带的一个简单却强大的 Web 压力测试工具。它是一个命令行工具,能够通过创建大量并发访问线程模拟多个用户对特定 URL 地址的访问,从而测试目标服务器的负载能力。
工具特点
轻量化:ab 工具对发起负载的本机要求很低。
易上手:命令行界面简单直观,学习曲线平缓。
核心指标:能够提供基本的性能指标,如每秒请求数和每次请求的响应时间。
缺点:不支持图形化结果展示,也不能实时监控。
使用方法
ab 的基本命令格式如下:
css
复制代码
ab [options] [http://]hostname[:port]/path其中,options 可以包括多种参数设置。在性能测试中,我们通常关注以下两个主要参数:
-n:设置测试中总共发起的请求数,即 Number of requests to perform。-c:设置一次产生的请求数(或并发数),即 Number of multiple requests to make。
例如,要对 http://example.com 进行测试,总共发起 1000 个请求,并且同时产生 100 个并发请求,可以使用以下命令:
arduino
复制代码
ab -n 1000 -c 100 http://example.com/结果解释
运行上述命令后,ab 工具会输出详细的测试结果,其中最重要的几个指标包括:
Requests per second:
该指标表示每秒钟处理的请求数,相当于性能测试工具 LoadRunner 中的每秒事务数。括号中的
mean表示这是一个平均值。计算公式:
Requests per second = 总请求数 / 总测试时间
Time per request:
该指标表示平均每个请求的响应时间,相当于 LoadRunner 中的平均事务响应时间。括号中的
mean表示这是一个平均值。计算公式:
Time per request = 总测试时间 / 总请求数
Time per request (concurrent):
这一行显示的
Time per request是每个连接请求实际运行时间的平均值。它的值等于上面行的Time per request除以并发数c。计算公式:
Time per request (concurrent) = Time per request / 并发数
修改好的代码可以同时执行两个客户端的请求,测试结果如下图:
在ab测试中,为了比较不同在并发数下我们的服务器的工作状态,我们选取 n=256,c 取 1,2,4,8,16,32,64,128,256 最后的测试
各种情况的截图如下
这是c=1
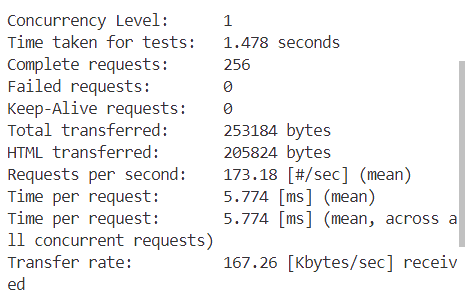
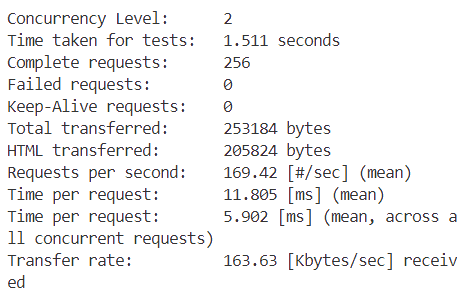
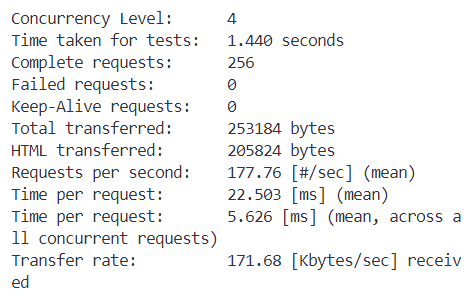
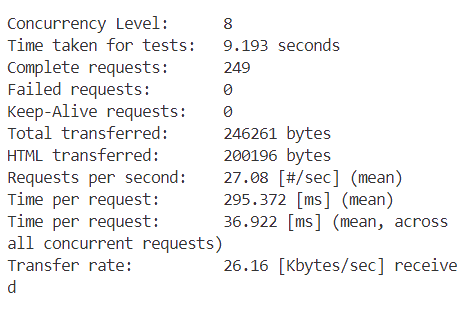
接下来分别是c=2,4,8....
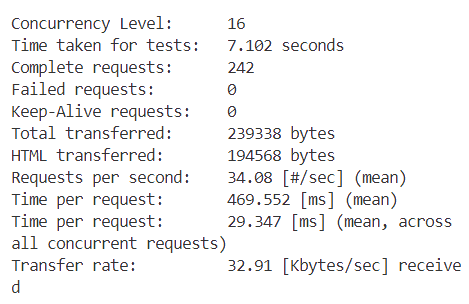
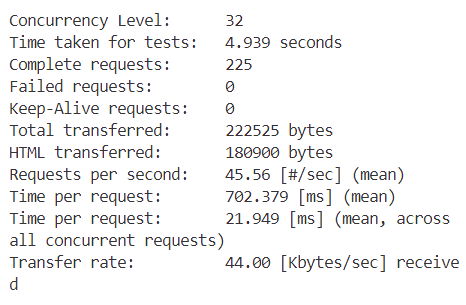
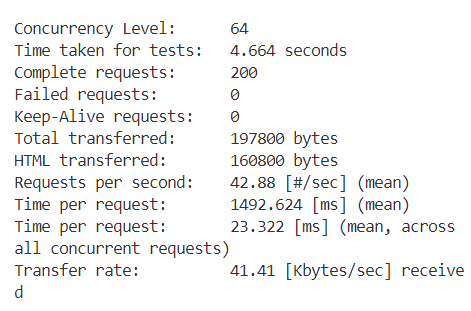
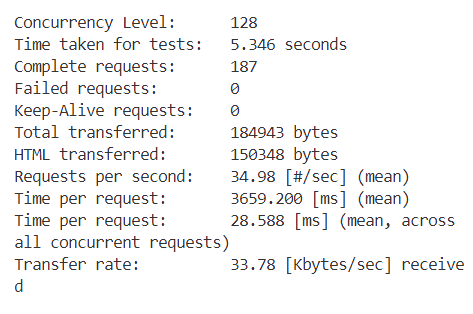
结果数据如下表所示
从表格中可以观察到,随着并发数的增加,我们的每秒请求数(Requests per second)也在不断增加。这意味着随着并发数的上升,每秒处理的事务数量也在增加。然而,当并发数达到32时,Requests per second达到了峰值,之后便开始下降。对于每个并发客户端的请求时间(Time per request)也是类似的趋势。一开始,随着并发数的增加,每个请求的平均处理时间在减少,直到并发数达到32时,Time per request达到最小值。随后,随着并发数的进一步增加,Time per request又开始上升,最终在并发数为256时达到了一个最高点。
测试平台截屏

评论